
“Transforme seus dados corporativos em aplicativos LLM prontos para produção”, anuncia a página inicial do LlamaIndex em formato de 60 pontos. OK então. O subtítulo é “LlamaIndex é a estrutura de dados líder para a construção de aplicativos LLM”. Não tenho tanta certeza de que seja o estrutura de dados líder, mas certamente concordo que é a estrutura de dados líder para construção com grandes modelos de linguagem, junto com LangChain e Semantic Kernel, sobre os quais falaremos mais adiante.
LlamaIndex oferece atualmente duas estruturas de código aberto e uma nuvem. Uma estrutura está em Python; o outro está em TypeScript. LlamaCloud (atualmente em versão prévia privada) oferece armazenamento, recuperação, links para fontes de dados via LlamaHub e um serviço proprietário pago de análise para documentos complexos, LlamaParse, que também está disponível como um serviço independente.
LlamaIndex possui pontos fortes no carregamento de dados, armazenamento e indexação de seus dados, consulta por meio da orquestração de fluxos de trabalho LLM e avaliação do desempenho de seu aplicativo LLM. LlamaIndex integra-se com mais de 40 armazenamentos de vetores, mais de 40 LLMs e mais de 160 fontes de dados. O repositório LlamaIndex Python tem mais de 30 mil estrelas.
Aplicativos típicos do LlamaIndex realizam perguntas e respostas, extração estruturada, bate-papo ou pesquisa semântica e/ou atuam como agentes. Eles podem usar geração aumentada de recuperação (RAG) para fundamentar LLMs com fontes específicas, muitas vezes fontes que não foram incluídas no treinamento original dos modelos.
LlamaIndex compete com LangChain, Semantic Kernel e Haystack. Nem todos eles têm exatamente o mesmo escopo e capacidades, mas no que diz respeito à popularidade, o repositório Python do LangChain tem mais de 80 mil estrelas, quase três vezes o do LlamaIndex (mais de 30 mil estrelas), enquanto o muito mais recente Kernel Semântico tem mais de 18 mil estrelas, um pouco mais da metade do LlamaIndex, e o repositório do Haystack tem mais de 13 mil estrelas.
A idade do repositório é relevante porque as estrelas se acumulam com o tempo; é também por isso que qualifico os números com “acima”. As estrelas nos repositórios do GitHub estão vagamente correlacionadas com a popularidade histórica.
LlamaIndex, LangChain e Haystack possuem uma série de grandes empresas como usuários, algumas das quais usam mais de uma dessas estruturas. O Kernel Semântico é da Microsoft, que normalmente não se preocupa em divulgar seus usuários, exceto para estudos de caso.
A estrutura LlamaIndex ajuda você a conectar dados, embeddings, LLMs, bancos de dados vetoriais e avaliações em aplicativos. Eles são usados para perguntas e respostas, extração estruturada, bate-papo, pesquisa semântica e agentes.
Recursos do LlamaIndex
Em alto nível, o LlamaIndex foi projetado para ajudá-lo a construir aplicativos LLM com contexto aumentado, o que basicamente significa que você combina seus próprios dados com um grande modelo de linguagem. Exemplos de aplicativos LLM com contexto aumentado incluem chatbots para resposta a perguntas, compreensão e extração de documentos e agentes autônomos.
As ferramentas fornecidas pelo LlamaIndex realizam carregamento, indexação e armazenamento de dados, consultando seus dados com LLMs e avaliando o desempenho de seus aplicativos LLM:
- Os conectores de dados ingerem os dados existentes a partir da origem e do formato nativos.
- Os índices de dados, também chamados de embeddings, estruturam seus dados em representações intermediárias.
- Os mecanismos fornecem acesso em linguagem natural aos seus dados. Isso inclui mecanismos de consulta para resposta a perguntas e mecanismos de bate-papo para conversas com várias mensagens sobre seus dados.
- Os agentes são trabalhadores do conhecimento alimentados por LLM e aumentados por ferramentas de software.
- As integrações de observabilidade/avaliação permitem experimentar, avaliar e monitorar seu aplicativo.
Aumento de contexto
Os LLMs foram treinados em grandes volumes de texto, mas não necessariamente em textos sobre o seu domínio. Existem três maneiras principais de realizar aumento de contexto e adicionar informações sobre seu domínio, fornecendo documentos, fazendo RAG e ajustando o modelo.
O método mais simples de aumento de contexto é fornecer documentos ao modelo junto com sua consulta e, para isso, talvez você não precise do LlamaIndex. Fornecer documentos funciona bem, a menos que o tamanho total dos documentos seja maior que a janela de contexto do modelo que você está usando, o que era um problema comum até recentemente. Agora existem LLMs com janelas de contexto de milhões de tokens, que permitem evitar passar para as próximas etapas de muitas tarefas. Se você planeja realizar muitas consultas em um corpus de um milhão de tokens, você desejará armazenar os documentos em cache, mas isso é assunto para outro momento.
A geração de recuperação aumentada combina contexto com LLMs no momento da inferência, normalmente com um banco de dados vetorial. Os procedimentos RAG geralmente usam incorporação para limitar o comprimento e melhorar a relevância do contexto recuperado, o que contorna os limites da janela de contexto e aumenta a probabilidade de o modelo ver as informações necessárias para responder à sua pergunta.
Essencialmente, uma função de incorporação pega uma palavra ou frase e a mapeia para um vetor de números de ponto flutuante; eles normalmente são armazenados em um banco de dados que suporta um índice de pesquisa vetorial. A etapa de recuperação então usa uma pesquisa de similaridade semântica, geralmente usando o cosseno do ângulo entre a incorporação da consulta e os vetores armazenados, para encontrar informações “próximas” para usar no prompt aumentado.
O ajuste fino de LLMs é um processo de aprendizagem supervisionado que envolve o ajuste dos parâmetros do modelo para uma tarefa específica. Isso é feito treinando o modelo em um conjunto de dados menor, específico da tarefa ou do domínio, rotulado com exemplos relevantes para a tarefa alvo. O ajuste fino geralmente leva horas ou dias usando muitas GPUs no nível do servidor e requer centenas ou milhares de exemplares marcados.
Instalando o LlamaIndex
Você pode instalar a versão Python do LlamaIndex de três maneiras: a partir do código-fonte no repositório GitHub, usando o llama-index instalação inicial ou usando llama-index-core além de integrações selecionadas. A instalação inicial ficaria assim:
pip install llama-index
Isso extrai LLMs e embeddings OpenAI, além do núcleo LlamaIndex. Você precisará fornecer sua chave de API OpenAI (veja aqui) antes de poder executar exemplos que a utilizem. O exemplo inicial do LlamaIndex é bastante direto, essencialmente cinco linhas de código após algumas etapas simples de configuração. Existem muitos mais exemplos no repositório, com documentação.
Fazer a instalação personalizada pode ser algo assim:
pip install llama-index-core llama-index-readers-file llama-index-llms-ollama llama-index-embeddings-huggingface
Isso instala uma interface para os embeddings Ollama e Hugging Face. Há um exemplo inicial local que acompanha esta instalação. Não importa como você comece, você sempre pode adicionar mais módulos de interface com pip.
Se preferir escrever seu código em JavaScript ou TypeScript, use LlamaIndex.TS (repo). Uma vantagem da versão TypeScript é que você pode executar os exemplos online no StackBlitz sem qualquer configuração local. Você ainda precisará fornecer uma chave de API OpenAI.
LlamaCloud e LlamaParse
LlamaCloud é um serviço em nuvem que permite fazer upload, analisar e indexar documentos e pesquisá-los usando LlamaIndex. Está em um estágio alfa privado e não consegui acessá-lo. LlamaParse é um componente do LlamaCloud que permite analisar PDFs em dados estruturados. Está disponível por meio de uma API REST, um pacote Python e uma UI web. Atualmente está em uma versão beta pública. Você pode se inscrever para usar o LlamaParse por uma pequena taxa baseada no uso após as primeiras 7 mil páginas por semana. O exemplo dado comparando LlamaParse e PyPDF para o arquivamento Apple 10K é impressionante, mas eu não testei sozinho.
LhamaHub
LlamaHub dá acesso a uma grande coleção de integrações para LlamaIndex. Isso inclui agentes, retornos de chamada, carregadores de dados, incorporações e cerca de 17 outras categorias. Em geral, as integrações estão no repositório LlamaIndex, PyPI e NPM, e podem ser carregadas com pip install ou npm install.
criar-lhama CLI
create-llama é uma ferramenta de linha de comando que gera aplicativos LlamaIndex. É uma maneira rápida de começar a usar o LlamaIndex. O aplicativo gerado tem um front-end com tecnologia Next.js e uma escolha de três back-ends.
RAG CLI
RAG CLI é uma ferramenta de linha de comando para conversar com um LLM sobre arquivos que você salvou localmente em seu computador. Este é apenas um dos muitos casos de uso do LlamaIndex, mas é bastante comum.
Componentes LlamaIndex
Os guias de componentes do LlamaIndex fornecem ajuda específica para as várias partes do LlamaIndex. A primeira captura de tela abaixo mostra o menu do guia de componentes. A segunda mostra o guia de componentes para prompts, rolado até uma seção sobre personalização de prompts.

Os guias do componente LlamaIndex documentam as diferentes peças que compõem a estrutura. Existem alguns componentes.

Estamos analisando os padrões de uso de prompts. Este exemplo específico mostra como personalizar um prompt de perguntas e respostas para responder no estilo de uma peça de Shakespeare. Este é um prompt zero-shot, pois não fornece nenhum exemplar.
Aprendendo LlamaIndex
Depois de ler, compreender e executar o exemplo inicial em sua linguagem de programação preferida (Python ou TypeScript, sugiro que você leia, entenda e experimente quantos outros exemplos parecerem interessantes. A captura de tela abaixo mostra o resultado de gerando um arquivo chamado essay executando essay.ts e fazendo perguntas sobre ele usando chatEngine.ts Este é um exemplo de uso de RAG para perguntas e respostas.
O programa chatEngine.ts usa os componentes ContextChatEngine, Document, Settings e VectorStoreIndex do LlamaIndex. Quando olhei o código-fonte, vi que ele se baseava no modelo OpenAI gpt-3.5-turbo-16k; isso pode mudar com o tempo. O módulo VectorStoreIndex parecia estar usando o banco de dados vetorial Qdrant de código aberto baseado em Rust, se eu estivesse lendo a documentação corretamente.
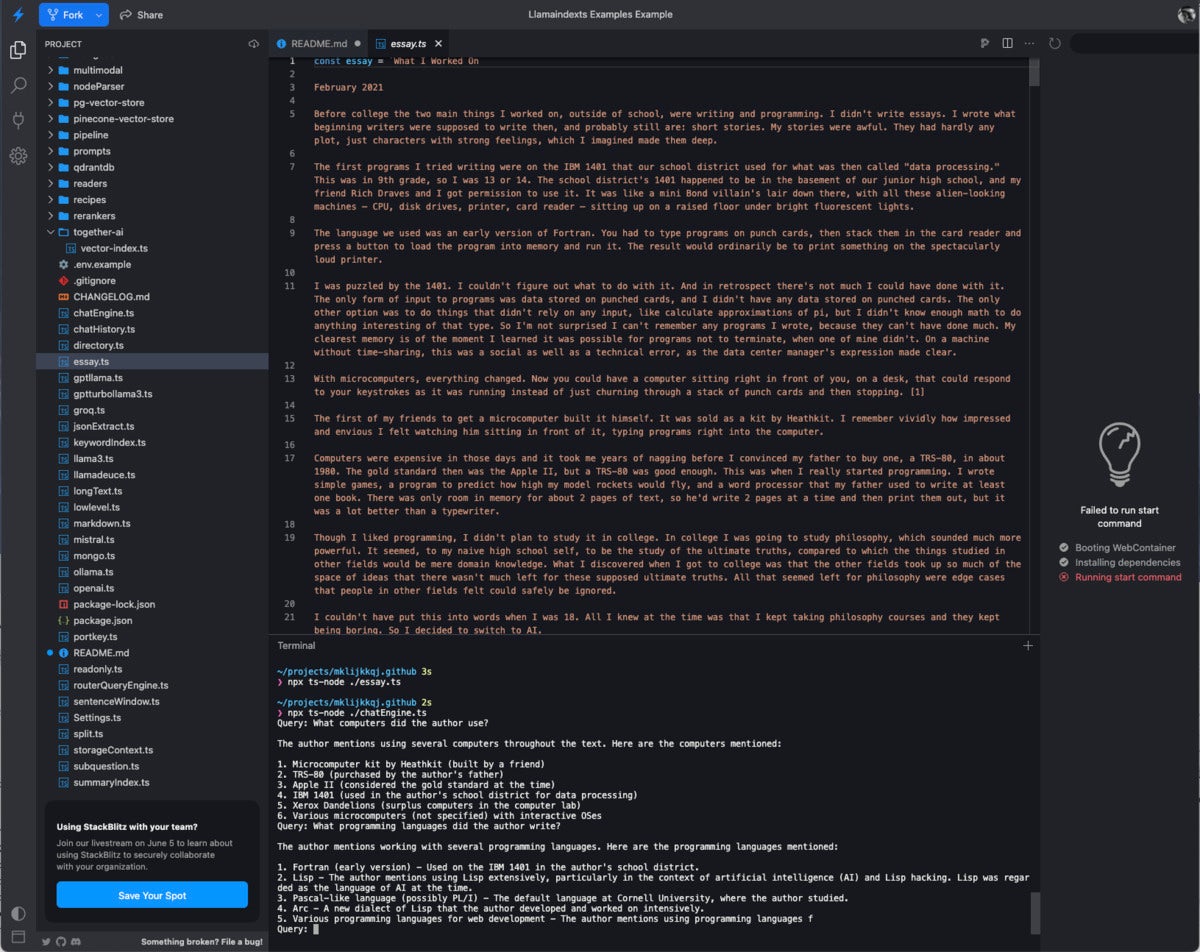
Depois de configurar o ambiente do terminal com minha chave OpenAI, executei essay.ts para gerar um arquivo de redação e chatEngine.ts para responder a consultas sobre a redação.
Trazendo contexto para LLMs
Como você viu, o LlamaIndex é bastante fácil de usar para criar aplicativos LLM. Consegui testá-lo em OpenAI LLMs e em uma fonte de dados de arquivo para um aplicativo RAG Q&A sem problemas. Como lembrete, o LlamaIndex se integra a mais de 40 armazenamentos de vetores, mais de 40 LLMs e mais de 160 fontes de dados; funciona para vários casos de uso, incluindo perguntas e respostas, extração estruturada, chat, pesquisa semântica e agentes.
Eu sugeriria avaliar LlamaIndex junto com LangChain, Semantic Kernel e Haystack. É provável que um ou mais deles atenda às suas necessidades. Não posso recomendar um em detrimento dos outros de uma forma geral, pois aplicações diferentes têm requisitos diferentes.
Prós
- Ajuda a criar aplicativos LLM para perguntas e respostas, extração estruturada, chat, pesquisa semântica e agentes
- Suporta Python e TypeScript
- Frameworks são gratuitos e de código aberto
- Muitos exemplos e integrações
Contras
- A nuvem está limitada à visualização privada
- O marketing é um pouco exagerado
Custo
Código aberto: gratuito. Serviço de importação LlamaParse: 7 mil páginas por semana grátis, depois US$ 3 por 1.000 páginas.
Plataforma
Python e TypeScript, além de SaaS em nuvem (atualmente em visualização privada).